
Linux下固定USB串口名称
以 USB 转串口的设备通常节点名为ttyUSBx(x为0~n),Linux 内核会根据设备插入的顺序进行分配。如果仅仅以设备节点ttyUSBx来区别是哪个设备,以为串口号是随时会发生改变的,没办法保证设备 A 就是 ttyUSB0,设备 B 就是 ttyUSB1。 我在使用 Rosmaster 驱动小车电机时,出现了串口不稳定的状况,不便于开发。所以我寻找了一个解决方案将 USB 串口名称映射为一个固定值。 udev 是 Linux kernel 的设备管理器,主要管理/dev目录下的设备节点。遂可以通过自定义 udev 规则为串口设备创建固定的符号链接,例如将需要的电机串口固定为dev/ttyMotor。 通过udevadm获取设备路径 12udevadm info --query=path --name=/dev/ttyUSB0# 输出示例:/devices/pci0000:00/0000:00:14.0/usb1/1-1/1-1.3/1-1.3:1.0/ttyUSB0/tty/ttyUSB0 记录下设备路径1-1.3:1.0。 创建自定义 udev...
RPC
RPCRemote Procedure Call 远程过程调用,是一种计算机通信协议,可以实现分布在不同服务器上的应用程序之间的调用,就像调用本地方法那样。 RPC调用流程 服务消费者 client 以本地调用方式调用服务 client stub 接收调用后负责将方法、参数等序列化成能够进行网络传输的消息体 client stub 将消息进行编码并发送到服务端 server stub 收到消息后进行解码 server stub 根据解码的结果反序列化并调用本地的服务 本地服务执行并将结果返回给 server stub server stub 将结果进行编码并发送给消费方 client client stub 收到消息并进行解码 服务消费方 client 得到结果 RPC 的作用就是将 2~8 步骤封装起来,用户无需关注这些细节,可以像调用本地方法一样即可完成远程服务调用。 RPC-动态代理使用 JDK 动态代理的核心是InvocationHandler接口和Proxy类。 InvocationHandler...

Netty高性能架构
网络线程模型不同的线程模型,对程序的性能影响很大,目前存在的线程模型有:传统阻塞 I/O 模型、Reactor 模式、Proactor 模式。 Netty 线程模式主要是基于主从 Reactor 多线程模型(多 Reactor 多线程)做了一定改进。 传统阻塞I/O模型传统阻塞式的最大特点是每个 client 的连接都需要独立的线程完成数据的输入→业务处理→数据返回。 它存在的两大问题是: 当并发数很大时,会创建大量的线程; 连接创建后如果当前线程没有数据可读,会一直阻塞在read操作,造成资源浪费。 Reactor模式Reactor 是一种高性能的网络模式,市面上常见的开源软件比如 Redis、Nginx、Netty 等都采用了这个方案。 Reactor 采用「资源复用」的思想解决 BIO 存在的两大问题: 不再为每个连接创建线程,而是创建线程池将连接分配给线程,一个线程可以处理多个连接的业务; 避免一个连接对应一个线程时,线程「read->业务处理->send」的处理流程在没有数据可读时会阻塞在read上。采用 I/O...
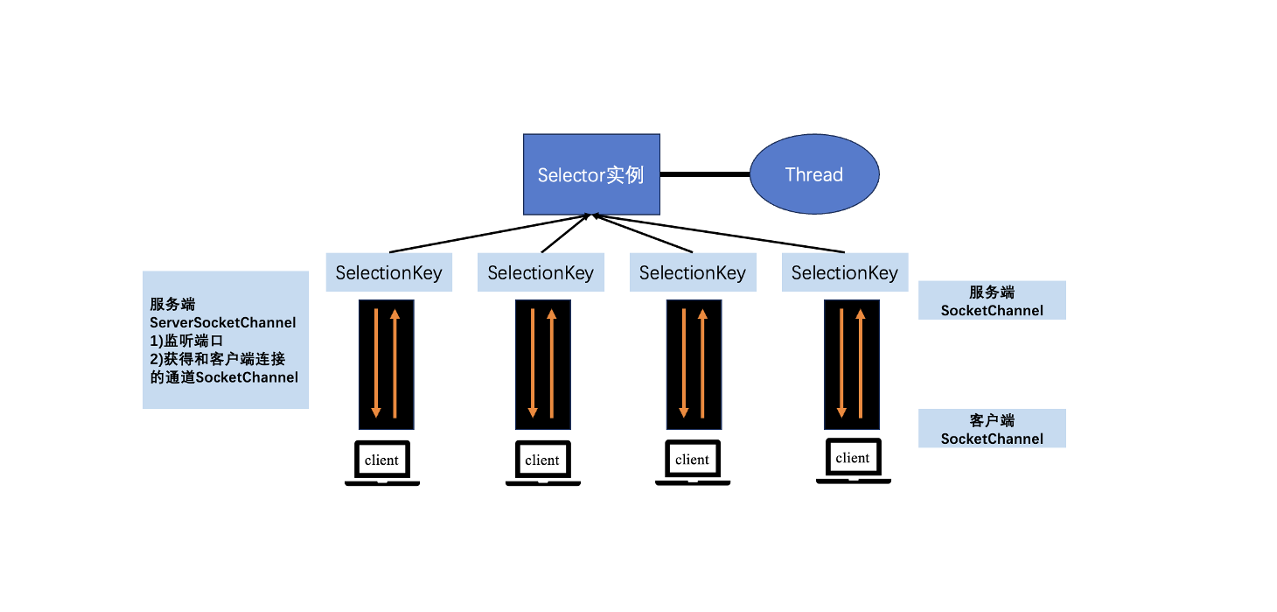
NIO编程
经过前面对 NIO 的介绍,我们理解 NIO 不会在数据没有准备好的时候一直阻塞线程,线程可以继续做其他事情。正是因为这个特点,NIO 可以做到通过一个线程来处理多个操作。 使用场景分析 BIO 方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4 以前的唯一选择,但程序简单易理解。 NIO 方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,弹幕系统,服务器间通讯等。编程比较复杂,JDK1.4 开始支持。 AIO 方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用 OS 参与并发操作,编程比较复杂,JDK7 开始支持。 NIO 的三大核心组件 每一个 channel 都会对应一个 Buffer; Selector 对应一个线程,一个线程对应多个 channel 连接; Selector 会根据不同的事件在各个通道上切换,因为程序切换到哪个 channel 是由事件决定的; Buffer 是一个内存块,底层是一个数组; 和 BIO 的输入输出流不同, NIO 的 Buffer...

ZooKeeper
ZooKeeper集群为了保证高可用性,最好以集群方式部署 ZooKeeper,官方架构图就是一个 ZooKeeper 集群整体对外提供服务。 每一个 Server 代表一个安装 ZooKeeper 服务的服务器,组成 ZooKeeper 服务的服务器会在内存中维护一个状态,并且每台 Server 之间都互相保持着通信。集群之间通过 ZAB 协议保持数据的「一致性」。 ZooKeeper集群角色在 ZooKeeper 中没有选择传统的 Master/Slave 概念,而是通过 Leader、Follower、Observer 三种角色: 角色 说明 Leader 为客户端提供读、写服务,负责投票的发起和决议,更新状态 Follower 为客户端提供读服务,如果是写则转发给Leader;参与选举中的投票 Observer 为客户端提供读服务;不参与选举投票,不参与“过半写成功”策略 Observer 观察者在不影响写性能的情况下(不参与“过半写成功”策略)提升集群的读性能。 Leader选举当 Leader...
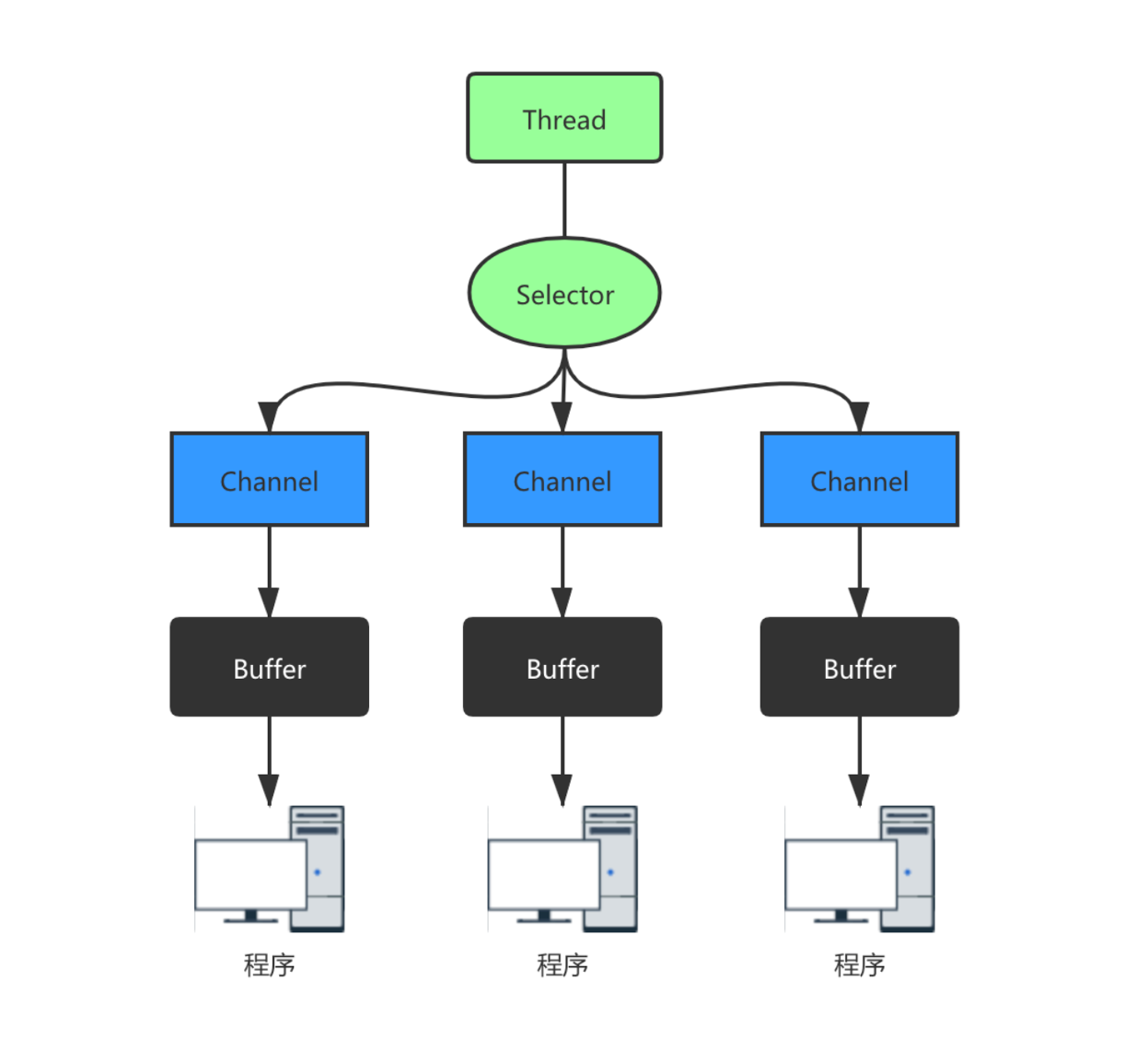
Java NIO
NIO(Non-blocking I/O 或者 New I/O),是一种同步非阻塞的 I/O 模型,也是 I/O 多路复用的基础,逐渐成为解决高并发与大量连接问题的有效方式。 传统的 BIO 模型传统服务器同步阻塞 I/O 处理(Blocking I/O)的经典模型是:BIO 同步阻塞模型通常使用多线程,这是因为socket.accept(), socket.read(),socket.write()三个主要 I/O 方法都是同步阻塞的,如果是单线程的话就只能挂死在那;开启多线程可以充分利用 CPU 去处理其他的事情。 多线程的本质:①利用多核特性;②当 I/O 阻塞系统,但 CPU 空闲的时候可以利用多线程使用 CPU 资源。 现在的多线程编程通常都基于线程池,可以降低线程频繁创建和销毁的成本开销,在活动连接数不是很多(单机小于1000)情况下是合理的,可以让每个连接专注自己的 I/O。 BIO 模型最本质的问题在于「严重依赖线程资源」,像 Java 的线程栈至少要分配将近 1M 的空间,如果系统的线程数过千整个 JVM...

设计模式
我理解的设计模式实际上是在某些编码场景下,针对某类问题的一种通用的设计方法和解决方案。设计模式有 23 种共分为三大类:创建型模式、结构型模式、行为型模式,这篇文章总结我用过的设计模式。 创建型模式单例模式单例模式保证一个类只有一个实例——如果你创建了一个对象,同时过一会儿后你决定再创建一个新对象,此时你会获得之前已创建的对象,而不是一个新对象;为该实例提供全局访问节点,允许在程序的任何地方访问特定对象。通过「双重检查锁」支持多线程创建单例对象: 1234567891011121314151617181920final class SingletonDemo { private static volatile SingletonDemo instance = null; // 禁用构造方法 private SingletonDemo() { } public static singletonDemogetInstance() { // 先判断实例是否存在 if (instance ==...
ThreadLocal机制
ThreadLocal为什么要有 ThreadLocal为了解决多线程存在「线程安全」的问题——线程并发对同一临界区的共享资源进行访问而导致的内存数据安全问题,才引入的 ThreadLocal——每个线程拥有自己线程隔离的「本地变量」。 ThreadLocal 中弱引用问题要说清楚 ThreadLocal 中的弱引用机制,还要从 ThreadLocal 的设计初衷讲起。为了解决多线程线程安全问题,每一个 Thread 中都有一个 ThreadLocalMap,其中 key 为 ThreadLocal 本地变量,value 为想要存放的具体值。为了实现线程安全,不允许用户直接接触 ThreadLocalMap 向里面 put Entry,而是通过 ThreadLocal 的 API:get、set、remove 来间接操作。具体的实现是,ThreadLocalMap 作为 ThreadLocal 中的静态内部类,ThreadLocal 为 Map 提供了外层的用户封装,而将可能出现的线程冲突交由内部实现来解决。 这就造成了当使用者没有正确的通过 remove 方法将...

消息队列选型
消息队列这是一篇对消息队列的详细总结(可能对于高可用和架构方面的总结还不够,未来会随着对知识理解的加深继续完善)。在项目中使用了 RabbitMQ,所以也记录了 RabbitMQ 的使用集成。 消息队列可以看成一个存放消息的容器,由于 Queue 是一种先进先出的数据结构,所以消息队列消费数据也是「按序」的。 消息队列基础消息队列有什么作用 这部分来自 JavaGuide 异步处理 将服务中一些「非核心的耗时业务」以异步方式执行,将消息加入消息队列中之后就立即返回结果,减少响应时间。 由于用户请求在将数据写入消息队列后就返回给用户,但是下游任务可能会因为各种情况而失败。所以在使用消息队列异步处理下游业务时还要进行一些流程上的修改——比如订机票、酒店时用户提交订单,后台将订单写入 MQ,不能立即返回订单提交成功,需要等待 MQ 中的订单消费者将订单出库后,再通过短信的方式通知用户。 为了保证消息队列中的消息被消费,会将消息缓存在生产者服务器的 buffer 中,直到收到消费者服务器的成功消费通知。 削峰 / 限流...

手写SpringBoot Starter
SpringBoot 自动装配用我的一句话总结自动装配就是:SpringBoot 通过起步依赖和自动装配机制来简化项目的构建和开发管理。 手动实现SpringBoot Starter步骤1 创建Maven项目创建新 Maven 项目,手动添加必要的 pom 依赖。 12345678910111213141516<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.3.7</version></parent><dependencies> <dependency> <groupId>org.springframework.boot</groupId> ...
